
In der Mastodon-API nennt sich ein Toot tatsächlich Status und so lässt sich gleich auch schneller die notwendigen Informationen zur Struktur und Inhalt eines Toot finden.
Ich möchte die Dokumentation hier nicht wiederholen, sondern nur auf ein paar wichtige Bereiche eingehen.
Noch mal das Beispiel aus dem letzten Blog-Artikel (gekürzt):
{
"id": 108243723640515608,
"created_at": "2022-05-04 12:42:26.372000+00:00",
"in_reply_to_id": null,
"in_reply_to_account_id": null,
"sensitive": false,
"spoiler_text": "",
"visibility": "public",
"language": "de",
"uri": "https://social.tchncs.de/users/beandev/statuses/108243723640515608",
"url": "https://social.tchncs.de/@beandev/108243723640515608",
"replies_count": 1,
"reblogs_count": 1,
"favourites_count": 1,
Neben den erwartbaren Attributen wie die ID, Daten der Erstellung, Sichtbarkeitseinstellungen und dem Inhalt der Nachricht selbst, finden sich einiges an Informationen, die erstmal überraschen könnten. Vor allem gibt es schon ein paar statistische Daten, wie häufig der Status favorisiert oder geboostert wurde. Daraus kann man schon mal eine Konsequenz ableiten. Wenn ein Toot über die API zu verschiedenen Zeitpunkten abgefragt wird, erhält man unterschiedliche Responses.
Schauen wir uns den Content an:
"content": "<p>Das ist ein Test, bitte ignorieren.</p>",
Da sind HTML Tags drin! Erinnern wir uns an den Befehl, den wir verwendet hatten:
response = mastodon.toot ("Das ist ein Test, bitte ignorieren.")
Da muss also was passiert sein. Zudem bedeutet das, es spricht nichts gegen HTML-Auszeichnungen in Nachrichten. Allerdings wird man das in keinem Micro-Blogging Client (für z.B. Mastodon) im Fediverse finden. Das ist eine Beschränkung, die andere Dienste (im Bereich des Publishing und Macro-Blogging) nicht haben (z.B. Friendica). Aber alle diese Dienste kommunizieren miteinander auf dem gleichen Protokoll ActivityPub und somit finden sich auf einmal HTML Tags im Content, die uns die API freundlicherweise angefügt hat. Das geht sogar noch viel weiter, wie ich noch später erläutern werde.
Nicht sehr überrascht es, dass man auch die Application als Information geliefert bekommt. Einige Clients zeigen das zu jedem Toot direkt an:
"application": {
"name": "Spielplatz",
"website": "https://social.tchncs.de/@beandev"
},
Als ich das erste Mal die Response zu den Timeline-Daten und Statusnachrichten gesehen hatte, überraschte mich am meisten, für jeden einzelnen Toot die Account-Informationen zu bekommen:
...
"application": {
"name": "Playground",
"website": "https://social.tchncs.de/@beandev"
},
"account": {
"id": 38900,
"username": "beandev",
"acct": "beandev",
"display_name": "Aljoscha Rittner (beandev)",
"locked": false,
"bot": false,
...
Das erscheint zunächst extrem kostspielig, so viele (eigentlich redundante) Informationen mitzuliefern, ist aber in der föderierten Struktur des Fediverse begründet. Es soll sichergestellt werden, dass jeder Client alle Daten, ohne weitere Rückfragen, zur Verfügung hat. Das ist konsequent implementiert, soweit es sich um textuelle Informationen handelt, bei Daten (Bilder, Videos, Soundstreams) erhält man trotzdem nur Referenzen. Der Vorteil ist, dass es den entfernten Host (Mastodon Instanz) vor vielen Anfragen zu Detailinformationen bewahrt, die extra Roundtrips benötigen (was eine summierte hohe Latenz bedeutet und den Host zusätzlich belasten würde).
Am Ende des Beispiel-Toots sehen wir noch ein paar zusätzliche Attribute:
...
"media_attachments": [],
"mentions": [],
"tags": [],
"emojis": [],
"card": null,
"poll": null
}
...
Die sind für unseren ersten Beispiel-Toot leer. Aber gerade diese Attribute haben eine enorme Bedeutung, zusammen mit dem Content.
Um etwas Praxis ins Spiel zu bringen, lesen wir mal einen anderen Status aus:
import json
from mastodon import Mastodon
mastodon = Mastodon (
api_base_url='https://social.tchncs.de'
)
response = mastodon.status (108247697988744452)
print (json.dumps(response, indent=4, default=str))
Im Browser sieht die Nachricht so aus:
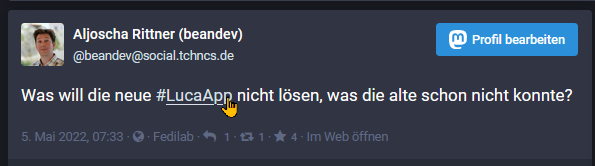
Es gibt einen Hashtag, der als Link anzuklicken ist. Nun ist das nicht eine besondere Fähigkeit des Browser-UI. Nein, dieser Link existiert wirklich in den Daten. Der Ausschnitt aus der Response unseres obigen Aufrufs:
"content": "<p>Was will die neue
<a href=\"https://social.tchncs.de/tags/LucaApp\"
class=\"mention hashtag\"
rel=\"tag\">#<span>LucaApp</span></a>
nicht l\u00f6sen, was die alte schon nicht konnte?</p>"
Da wurde also aus einer einfachen Textzeichenkette mit einer ‘#’ Auszeichnung gleich ein ordentliches Stück HTML.
Nun der Blick ans Ende der JSON Struktur:
...
"media_attachments": [],
"mentions": [],
"tags": [
{
"name": "lucaapp",
"url": "https://social.tchncs.de/tags/lucaapp"
}
],
"emojis": [],
"card": null,
"poll": null
}
Dort ist der Hashtag-Ausdruck als tag aufgelistet. Der Name des tag ist in den Daten nur in Kleinbuchstaben beschrieben und dazu gibt es noch ein URL-Link zur Hashtag-Timeline der Mastodon-Instanz.
Die Mastodon-Instanz mit ihrer API betreibt also einen großen Aufwand, um aus den neuen Toots bestimmte Informationen zu parsen, diese in HTML umzuwandeln und zugleich diese geparsten Elemente strukturiert zur Verfügung zu stellen.
Das wird auch mit @ annotierte Erwähnungen gemacht, den Dateien (wie Bilder und Videos) und den auf Mastodon-Instanzen individuellen Emoticons.

Comments
No comments yet. Be the first to react!