
Einführung
Für einen schnellen Einstieg in OpenSearch (dem Open Source Fork von ElasticSearch) ist es sinnvoll, sich das in einer Container-Umgebung aufzubauen. Inzwischen gibt es recht viele Container-Dienste (nicht nur Docker), aber für Entwickler ist das häufig immer noch die schnellste Methode, deswegen belasse ich es hier dabei.
Dieser Blog soll auch keine große Einführung in Docker werden. Da gibt es sicherlich eine Menge an Quellen. Ich gehe davon aus, dass eine aktuelle Docker Version lokal installiert ist. Das ist für alle gängigen Betriebssysteme möglich, sogar für Windows. Allerdings hat das Windows Subsystem kleinere Fallstricke, die man aber gut umschiffen kann. Dazu später mehr.
Portainer-CE als UI
Wenn man nicht sehr oft in der Docker-Kommandozeile unterwegs ist, kann es hilfreich sein, eine UI zur Administration einzusetzen. Ich nutze da gerne Portainer-CE. Auch Portainer-CE selbst wird als Docker Image ausgeliefert und hat eine gute Installations-Dokumentation. Für Entwicklungsrechner sollte eine Docker Standalone Installation reichen, Docker Swarm oder Kubernetes braucht es da nicht.
OpenSearch Single-Node für Entwickler
OpenSearch ist ein Framework für hochverfügbare, verteilte Persistenz- und Suchdienste für JSON Dokumente. Die JSON Dokumente sind selbst eine Sammlung von Attributen, die zu dem Zweck gespeichert werden, genau mit diesen Informationen wiedergefunden zu werden. Zu diesen Dokumenten legt OpenSearch einen Index (sowas wie ein Inhaltsverzeichnis) an, der diese Suche optimiert. OpenSearch ist explizit dazu gedacht, diese Aufgaben auf mehrere vernetzte Knoten zu verteilen (Cluster). Das wird man in produktiven Systemen auch immer so machen, allerdings nicht unbedingt lokal für Entwicklung und Tests.
OpenSearch bietet auf seiner Webseite mehrere Docker Compose Scripte an, die unterschiedliche Szenarien abbilden. Ich werde hier nicht das Rad neu erfinden, sondern empfehle schlicht das Compose Script für Entwickler zu nehmen:
version: '3'
services:
opensearch-node1:
image: opensearchproject/opensearch:1.3.1
container_name: opensearch-node1
environment:
- cluster.name=opensearch-cluster
- node.name=opensearch-node1
- bootstrap.memory_lock=true # along with the memlock settings below, disables swapping
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" # minimum and maximum Java heap size, recommend setting both to 50% of system RAM
- "DISABLE_INSTALL_DEMO_CONFIG=true" # disables execution of install_demo_configuration.sh bundled with security plugin, which installs demo certificates and security configurations to OpenSearch
- "DISABLE_SECURITY_PLUGIN=true" # disables security plugin entirely in OpenSearch by setting plugins.security.disabled: true in opensearch.yml
- "discovery.type=single-node" # disables bootstrap checks that are enabled when network.host is set to a non-loopback address
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536 # maximum number of open files for the OpenSearch user, set to at least 65536 on modern systems
hard: 65536
volumes:
- opensearch-data1:/usr/share/opensearch/data
ports:
- 9200:9200
- 9600:9600 # required for Performance Analyzer
networks:
- opensearch-net
opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:1.3.0
container_name: opensearch-dashboards
ports:
- 5601:5601
expose:
- "5601"
environment:
- 'OPENSEARCH_HOSTS=["http://opensearch-node1:9200"]'
- "DISABLE_SECURITY_DASHBOARDS_PLUGIN=true" # disables security dashboards plugin in OpenSearch Dashboards
networks:
- opensearch-net
volumes:
opensearch-data1:
networks:
opensearch-net:
Im Zweifel benötigt man nicht mal das opensearch-dashboard (Das Pendant zu ElasticSearch Kibana), hilft aber manchen, sich auf dem Index zurechtzufinden. Als Alternative zu dem Dashboard kann man evtl. auch Elasticvue ausprobieren.
OpenSearch Mit Portainer-CE deployen
Unter Portainer-CE installiert man Compose Scripte als Stack. Also an Portainer-CE anmelden, vom Dashboard die lokale Umgebung auswählen und im linken Menü Stacks auswählen. Mit Add Stack kann man nun den Stack definieren.
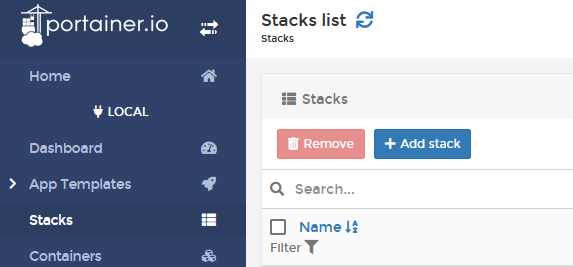
Man muss nur noch einen Namen festlegen (z.B. opensearch-1-3-1) und das Compose Script einfügen und dann “Deploy to Stack” anklicken. Das dauert jetzt etwas (weil auch die Images geladen werden). Bitte nicht selbständig die Seite verlassen, einfach warten.
Ist das Deployment abgeschlossen, ist man wieder in der Stack-Liste, dort klickt man die opensearch-1-3-1 an, um die Details zu sehen. Unten finden sich die Container des Stacks:
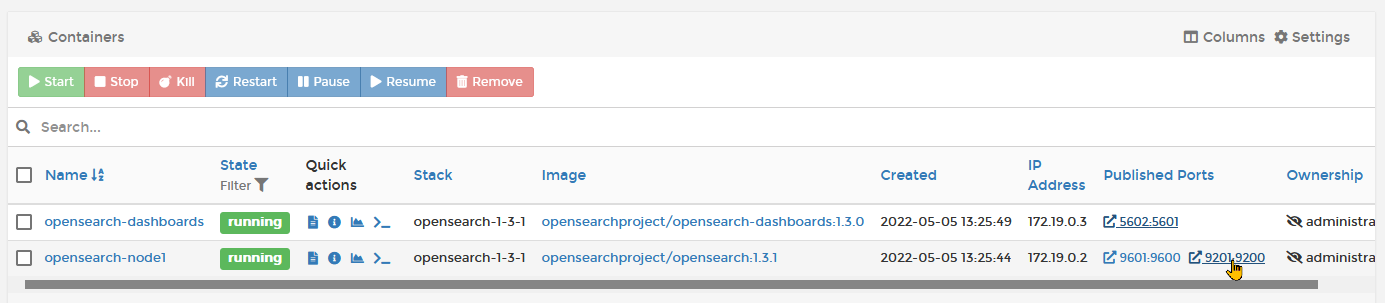
In der Spalte rechts finden sich die Published Ports und je nachdem, ob das Original Compose Script verwendet wurde (oder ob es angepasst wurde, wie ich es machte, da die Ports bei mir schon belegt waren), kann man zumindest jetzt sehr früh den Link mit 9200:9200 anklicken. Das ist einer der offenen Endpunkte des node1.
Es sollte dieses JSON angezeigt werden:
{
"name" : "opensearch-node1",
"cluster_name" : "opensearch-cluster",
"cluster_uuid" : "c1rhj_TsQZKRaBnerTLcvA",
"version" : {
"distribution" : "opensearch",
"number" : "1.3.1",
"build_type" : "tar",
"build_hash" : "c4c0672877bf0f787ca857c7c37b775967f93d81",
"build_date" : "2022-03-29T18:34:46.566802Z",
"build_snapshot" : false,
"lucene_version" : "8.10.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "The OpenSearch Project: https://opensearch.org/"
}
Nach ein paar Sekunden kann man auch (ohne Fehlermeldung) den Link zum Dashboard öffnen:
Da wir aber noch keine Daten drin haben, macht es keinen Sinn jetzt mit dem Dashboard anzufangen. Allerdings hat das Dashboard schon für seine internen Angelegenheiten einen Index angelegt.
Die Liste der Indizes bekommt man mit der URL http://127.0.0.1:9200/_cat/indices?v und zeigt eine schlichte Tabelle an:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana_1 oPhh4WkXTha54EXU4SdJ7A 1 0 1 0 4.9kb 4.9kb
Nun existiert ein Testsystem, dass wir für die nächsten Experimente nutzen können.

Comments
May 5, 2022 12:21
@bafpudvhe
OpenSearch ist der Fork von ElasticSearch und ist eine dokumentbasierter Suchindex. Du speicherst in OS immer in JSON strukturierte Daten (Dokumente) und definierst für die Strukturen einen Index, der dann mit einer Suchsprache extrem schnell durchsucht werden kann. Wird für Such-Cache "langsamer" Datenbanken und zu Analyse von großen Datenmengen verwendet.
@beandev@write.tchncs.de
May 5, 2022 12:27
@bafpudvhe
Würde ich nicht sagen. Aber manchmal ist das in entsprechender Software schon mit eingebaut. Einige NAS nutzen das von Haus aus, um eine Suche deiner Dateien zu verbessern. Dann manchmal aber direkt über Apache Lucene, ohne extra Dokumente zu erzeugen. Es liegt auch ein wenig am Spieltrieb, ob man das daheim benötigt. Im Unternehmensumfeld ist es schon recht häufig eingesetzt. Auch im DevOps Bereich.
@beandev@write.tchncs.de
May 5, 2022 12:31
@bafpudvhe
Oder man ist im DevOps Bereich unterwegs. Dort werden gerne Log-Daten verwaltet. Auch wissenschaftliche Daten aus Sensoren werden darin aufbereitet. Suchindexe für Textdokumente usw. usf.
@beandev@write.tchncs.de
May 5, 2022 12:34
@bafpudvhe
Was man ja dann lokal in den eigenen Cache kopieren kann ;-)
@beandev@write.tchncs.de